Software Development Progress
April 17th, 2007 by Claes-Fredrik
 On the software side, we’ve also undergone quite a bit of evolution.
On the software side, we’ve also undergone quite a bit of evolution.
In its previous incarnation, the Exbiblio system comprised components written using a variety of computer languages and technologies, such as C, C++, Objective-C, C#, AppleScript, Visual Basic for Applications, and Java (many or all of which will resurface over time). We were trying to leverage each contributor to their fullest by keeping them working in their most familiar environment, at the cost of more complex communication between the components. We were also trying to build in a lot of flexibility by having separate processes communicating with each other, at the cost of simple installation and maintenance.
In the current version of the software, we are aiming at a few simple goals:
- Keep as much code as possible both cross-platform (Mac OS X, Linux, Windows) and cross-node (pen, customer machine, server) by using C and C++.
An interesting point about our architecture is that we will over time be moving more and more functionality closer and closer to the customer. For example, we envision having the user get feedback on their pens immediately if we find the text they are currently scanning in our index. Indices and document text should be able to exist anywhere in the system, and migrate. - Provide simplicity, scalability and flexibility by defining a simple set of service interfaces that are then implemented to various extents on the pen, on the customer machine and on servers. These service interfaces have a separate configuration part which handles any necessary configuration, such as picking which service providers to use.
We started out with the search index and markup functionality being services, but we now think of pretty much everything as a service, including image processing and capture storage.
This has some very nice and interesting consequences, such as the ability to master and back up capture storage anywhere in the system, as the customer wishes, and the ability to farm out or pass along difficult jobs as needed and permitted by privacy settings.
It also means that the Life Library UI is completely independent of where its data comes from, whether from the pen, from the local disk, or over the network. The UI is always responsive since it runs in its own thread, and only the currently viewed (and surrounding) captures are retrieved from storage, so you can scroll through the captures as if they were all there, but we minimize local memory requirements, and allow for capture storage in the Internet cloud. - Bundle as much as possible into a single application on the customer machine, to simplify things for the user.
We will still have a few files out in the file system (often simply links back to files within our application bundle) since they are needed by Mac OS X, such a system preferences pane, and context menu code, but you can install our application by simply dragging it wherever you please, and double-clicking on it.
We’re toying with the idea of being clever about uninstalling the outlying aliases/links automatically as well, but cleverness can sometimes backfire and hurt customers, so we’ll need to be cautious there. - Provide a rock-solid communication protocol between the compute nodes, guaranteeing delivery.
In Falstaff, we didn’t put enough effort into ensuring that the communication between the pen and customer machine was solid, and have had problems of an intermittent nature that were very difficult to deal with. - Migrate software from host computers to the pen, after it’s been thoroughly analyzed and tested.
Even though debugging environments for embedded systems have advanced a lot, you still get a better developer experience on a desktop computer, so we are developing as much as we can in an environment that is independent of the hardware platform.
This is also greatly enhanced by the choice of Linux as our operating system on the pen. - Log extensively at every point in the system, to allow difficult problems to be fixed more easily.
We collect the logs and captures on a server, where we can sift through the logs, and harvest captures for automated test runs, so that we can both improve our success rate, and make sure we don’t decrease the success rate of our services. - Aim high and deliver.
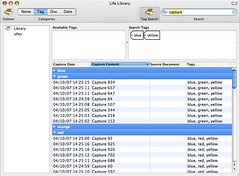
The screenshot in this post shows a first rough draft of a tag and keyword searching UI in the Life Library.
 Posted in Software Development | Comments Off on Software Development Progress | Other posts by Claes-Fredrik
Posted in Software Development | Comments Off on Software Development Progress | Other posts by Claes-Fredrik